A riff on Moshe Zadka’s blog post, using new Python features to answer the riddle from the movie Labyrinth. I learned a thing or two!
I had to look up the word (and it became a Word of the Day). Palimpsests are objects that are written on more than once, with the earlier writing not fully erased, often legible. Code evolves incrementally, one bug at a time, one new feature at a time, usually at the hands of multiple people. Any real piece of software has a lot of history embedded in it’s source.
Another creative merger between software and literature in the tradition of Pierre Menard, Inventor of LISP from Alvaro.
If you’re writing Python, having good tests matters a lot more than if you’re coding in a statically typed language like Java or Go. The language constrains you less, and it’s easy to shoot yourself in the foot. You’re already testing anyway, but doing it manually. Here, Ned provides a really good end to end overview of how to structure your code to make testing easier, and how to think about testing more generally as you develop your codebase.
Our rules should constrain us, because the more decisions we can make the more likely it is that we will shoot ourselves in the foot. Often, the way people think about this problem is naive.”The rhetoric around [simplicity] is tautological: ‘Do the simple thing.’ ‘Which one is that?’ ‘The simple one, isn’t it obvious?’” If it were, this blog post would not exist
The kinds of things people can do with CSS are amazing. I can barely center a div.
A pretty creative way to build placeholder images. I might try to build this into my website at some point.
Many years ago, I was really into the idea of pixel art, sometimes even building things out of lego. I found this project while trying to help one of my coworkers with his own crafts project.
Programming is about language, and much more about communicating to others, including our future selves, than about communicating with the machines that run our code. We translate our ideas into abstractions, taxonomies, and hierarchies, but those don’t necessarily map well onto the real world. There are always edge cases.
A lot of our decision making processes are based on the idea of voting occurring in a single snapshot, whether that is for boardrooms or national elections. What kinds of structures can emerge once we remove a few constraints?
I never got into the Knuth cult, I have not read his books, and don’t pretend to know much about his research, but I know he’s a highly influential figure who changed the field of computer scince again and again in the last ~60 years. Reading about him, and how he spends his time these days was fascinating.
This is a topic that I’ve been thinking a lot about at work, given the growth of my team and the trajectory that we’re following as a data platform to other teams within the company. I can’t say much, but I’m glad other people have thought about these problems before.
The ecosystem of built-ins and open source libraries around different programming languages can make solving certain problems trivial or nearly impossible. While we should be able to express the same ideas across any turing complete language, thinking of concurrency in Go or Erlang is much simpler than in C or Python. As Alvaro explains, this is not so much because of the language itself acts as a lens through which we see the world, but because each language (and its community!) packages different groups of ideas into self-contained tools and abstractions. When a Java programmer switches over to Lisp, they bring with them a bunch of ideas about how programming should be done, and while they are constrained by the framework of their new tool they also inject their own set of constructs into their new community by creating libraries that others can use and work on top of. In my opinion, the work you can do with a language depends much more on its ecosystem of bolted on tools than its basic syntax.
One of the most fundamental tools for modern software development had a major security hole, and as usual the issue was a human one, not a technical one.
This piece complains that Siri, Alexa, and the rest of the AI assistant pack can’t handle multiple languages. I fundamentally disagree with some of Larkin’s points. It’s a problem I experience often myself as a native Spanish speaker trying to communicate with these standard written english bots, so I totally understand where she’s coming from. However, not even addressing the speech to text part (which is what’s really broken with the accents), there just aren’t as many NLP tools/corpora/tagged datasets in other languages as there are in English. This is in part a historical/path dependence problem, and in part just economics. Can’t go much deeper than that, sadly.
I didn’t know that Solem, the creator of Celery, is now working at Robinhood, but having used it for a bunch of things while in college, and then again at my last gig, I’m looking forward to testing out his code. From their docs, “Faust provides both stream processing and event processing, sharing similarity with tools such as Kafka Streams” and it runs modern python (3.6+ only) with RocksDB and uvloop under the hood. This is a project I’m very excited to try out.
Say what you want about 10X engineers being a fantasy, but I’m convinced Michael Fogleman is one of them just by looking at his open source side projects. Here’s yet another super cool project from him that you should check out.
This is a wonderful post about how computer science concepts are abstracted over again and again, making it much easier to build things without knowing the details of what happens under the hood. It made me think of Alfred North Whitehead’s quip: “Civilization advances by extending the number of important operations which we can perform without thinking about them.” It also reminded me of an essay about constraints in programming and how over time we’ve decreased the surface of what a programmers can do, enabling them to do what they actually want to do more easily.
This conversation tries to showcase philosophies and practices from the software engineering world to a less technical audience, but does end up going in the weeds. The main idea behind dev-ops is one I subscribe to: empowering engineers to not only be in charge of designing and building a new feature, but also of deploying it, measuring its reliability, and owning its delivery throughout its life. By virtue of having one group of people responsible for the whole life cycle, there is an alignment of incentives that leads to more reliable, easier to deploy software.
This is one of those topics that confused me for a long time about Python. Ned’s post is more of a description of the lay of the land than an explanation of how and why things work the way they do in Python, but it has inspired me to go and dig through those bytecode talks he linked to, and learn more about Python internals.
If you haven’t read Borges’ Pierre Menard (that’s the original, for an English translation, click here), you should. The text provides amazing commentary on authorship, creativity, and intellectual property. In his piece, Alvaro takes it a step further - Pierre Menard’ing Menard, and rewriting the story as an allegory of computer science in the spirit of Borges. It’s just amazing.
I constantly remind my team to try to get into a beginner’s shoes when writing documentation, and to think carefully of every word they’re using when documenting code. My go to is “What would you think if you read that on your day 1 at the office?” Thinking about this problem at a more macro scale (i.e., all people learning python, not just seasoned engineers learning the ins and outs of a large system they’ll help develop) makes for an interesting change of perspective.
This post, and it’s follow-up made rounds on the python speaking part of the internet this week. It reminded me of Adrien Guillo’s post on the internals of Python strings. The little optimizations that happen under the hood can lead to surprising and unexpected behavior, but once you learn the deterministic rules behind the nice API, it is easy to predict how things will work, and you can use that to your advantage. Now I’m trying to decide how to optimize my current project with string interning.
One of those articles that make me wish I had been a CS/CE major. The things we do to make computers go fast are crazy.
On call rotations are about aligning incentives. Code that is suspected to have bugs is never merged and pushed to production on a Friday afternoon when the person writing it is on the hook to fix the error over the weekend. In my two years at Apple I have learned a lot about monitoring and logging, and one of the biggest lessons has been to write fool-proof error messages for anyone else in the team to quickly get context and all the information needed to debug without thinking too much. The post is full of other examples.
Another fun visualization experiment by Fogleman. How many widgets can one pack in a constrained volume? Math can give you the answer.
Identity online is hard - and I don’t mean tying your persona to social media, but actually tagging bits and bytes with other bits and bytes to identify them across machines. The self-incrementing column of integers is a mainstay of traditional databases, but what happens when scaling across machines becomes necessary? Here’s some history of how that’s been solved across the years.
Thinking about technical complexity as a moat is interesting, especially considering the initial discussion about “the shape of the cost-functionality curve.” I definitely believe that there are increasing costs to adding functionality, or as the author says “Features interact — intentionally — and that makes the cost of implementing the N+1 feature closer to N than 1.” This is exactly why a startup can come up with a simple product and blow a big co out of the water. They don’t have to worry about how all the other pieces in the business - and in the code! - interact with each other.
Stochastic modeling is a really cool topic, and here we see it applied to the transitions between programming languages.
These one-off explanations of snippets of source code are always enlightening. Coding seems like magic, until you discover that there is not magic, just layers upon layers of well thought out abstractions, each one understandable on its own, but magical as a whole.
Filing bugs sucks, every time, but few things are as satisfying as getting a message that says “this will be fixed in the next build!” and feeling like you’re helping improve a system that you actively use. Whether it is opening an issue on an open source project, or filing a Radar for a different team at Apple, the less I have to think about how to report a bug, the more likely it is that I will continue using your software, and helping you improve it.
Language matters. Names shape how we think. This is as important in computer science as in any other field. We talk about queues and stacks and bugs and patches, not because we like jargon, but because metaphors are the only way we can get complex ideas across quickly. Communication is the hardest thing about software engineering, and pretty much any human endeavor. Picking the right metaphors can ease our job significantly, and shed light on how others have solved the same problems in the past.
I’ve never even thought that disabling garbage collection could be a sensible option. It’s always fun to see how people can take a deep-dive into the inner workings of their toolchain and come out with this kind of performance boost. Questioning basic assumptions can be a good idea.
When Brett started posting a bunch of polls on how people use various Python libraries for HTTP requests, I knew he was up to something good.
Time is complicated, especially in massively distributed computing systems. I’d love to understand this topic better. If you have recommendations on what else to read, please let me know.
These past weeks I’ve been looking at a lot of hex, and a lot of bytes. Sometimes, weird patterns pop up when you least expect them to.
I’d wager that this is the hardest problem in all human endeavors, and not just in CS. Communication is hard, and while language helps us share our ideas, it is nearly impossible to be sure that the message we wanted to get across was properly conveyed.
While I am not a swift-er yet (is that a thing?) I am slowly picking up functional programming, and I find the ideas in this talk quite valuable.
Reading about graphics and procedural generation has become a new hobby for me.
I agree with Ghica. We need research into whether strong, static type systems help or hurt. When do we pick which? The issue is that any empirical study would have to control for training, use case, and many other variables. The end result would be to artificially recreate industry, which is basically impossible.
Me either.
Writing software is a matter of trade-offs. There are costs to runtime errors, but there are also costs to over engineering. In the end, each feature, and each project ends up mixing and matching processes and strategies, but I haven’t seen types pay-off their upfront expenses yet. Someone should spend the time modeling these choices in an economic model. I am sure several companies would be willing to fund such research.
Holding others in contempt for not working with a real language is a problem. Putting down PHP, a commonplace occurence, is as bad as mocking Java for having industrial strength. As a Python guy, I constantly get comments on when I’ll graduate to a static language. Making fun of each other’s tools of choice, and marking them as being beneath consideration is a mistake.
A critique of Spolsky’s Finding Great Developers, based on solid microeconomics. Luu compares the software engineering labor market to Akerlof’s market for lemons. The argument against Spolsky’s model seems to be based on two ideas: first, that there is an information asymmetry for both hiring managers, as well as engineers, and second, that the proportion of dysfunctional teams is larger than Spolsky implies. The article goes into an extensive study of the market structure, and possible solutions for both managers and engineers. The main takeaway, is that job hunting and hiring for software engineers is hard.
If there is one thing I have learned over the last year, it is that even small projects require huge overhead when your tolerance for error is small. Building services with acceptable uptime, reliablity, and performance is extremely complicated, if not nearly impossible. “I could do that in a weekend” is a strawman. In fact, I have come to the opposite realization… it is surprising that anything works at all, even when thousands of human hours are invested!
As usual with Maciej, there are many layers to this essay. The comparisons between libraries and the internet are not new, and his railing against large companies aiding online surveilance are more than expected. Much more interesting are the questions brought up about archiving the modern web - where content is selected, joined, and rendered dynamically per user at load time, with large portions behind walls: What is the point of building a community you don’t own? What should be kept for posterity? What is a the point of a site’s snapshot without the code that makes it work? What happens when a company dies, or misses, and we go beyond simple link-rot? The conclusion is hand wavey, but the future of the internet is, as Maciej put it, contingent.
In python, everything is a dict. Understanding how they work is really important, beyond the basic idea of hashing keys and mapping to values. This article by should be required reading.
I have been helping a friend level up his python recently, focusing on web development with Flask. One of his first questions? “What does @app.route, do?”
Slowly, one abstraction at a time, software engineering has become more and more accessible. The advent of Ruby on Rails marked the beginning of a wave that lowered the barriers to entry for programming, particularly web development, for thousand of engineers. I am one of them. Now it is time to put in the hours and master the craft.
Starting a career in software engineering during the days of AWS and Heroku gives me a strange vantage point. The story of how Netflix switched their whole infrastructure would not be half as impressive if I didn’t understand the role of culture in organizational change. The fact is that “this is how we do things around here” can make or break you. This episode talks about the architecture that underlie the modern web stack.
Another one that I can’t comment much on, but want to share.
Naming things is much harder than it seems, and its implications much more widespread than one would expect. Spend more time thinking about names.
Different languages have different ways of constraining and enabling programmers. Any language provides us with trade-offs. For a long time, I have thought of types as an added layer of complexity, which makes them unappealing. However, unit tests and documentation are also extra complexity, and I am more than happy to pay the cost for those. Perhaps its time to make the jump and get into static typing.
Software engineering, and the tools required for it, have evolved significantly over time. Barriers to entry have been lowered, making programming accessible for “normal” people, both in terms of monetary costs as well as in the amount of effort required to get started and build something significant. For better or for worse, modern programming languages are english-like enough that they can be grokked by children. Writing machine or assembly language can be seen as an esoteric exercise by today’s standards. On the shoulders of giants, we’ve climbed up several levels on the ladder of abstraction, and as Wenger implies, this is not stopping any time soon.
A follow-up on last week’s post on Docker, and the state of distributed systems on the web. This one being the non-satirical version.
Overengineering is a real problem. I need to learn more about this new dev-ops world, and play with Docker et al, but the fact is that to get started, a monolith running on Heroku is more than enough. Scaling will be harder? Yes, but you might actually get something done and sell to real users. Good enough is good enough. Once again, short-term vs. long term incentives.
Perspective on software engineering impact: Somehow, the industry keeps moving forward as our projects die, 1 by 1. Stay motivated, and learn from your errors.
Math lets us do some really interesting things. This post presents a relatively simple model that solves a real problem for a real person.
It is always interesting to see how others do things. Especially interesting is the migration from python/node to Java/Go, and the heavy usage of OSS projects. I agree that having less languages is good, however, this might be a bit quixotic.
The evolution of programming languages depends not only on what new languages allow you to do, but what they don’t. Taking away an engineer’s ability to do X also removes a concern from the picture. Thinking about less things at once means you can focus more on what’s left.
Another in depth look at modern solutions to artificial intelligence and problem solving. As usual, Karpathy makes complex ideas understandable, this time using OpenAI’s Gym to play Pong.
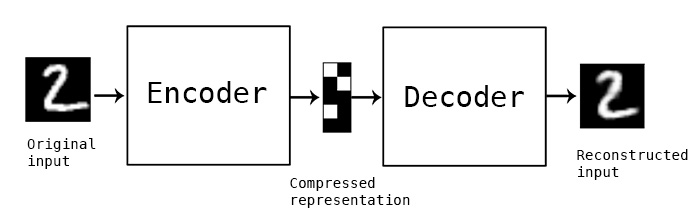
The application of these simple machine learning concepts keep impressing me more and more. Autoencoders are a very simple idea. If anything, click through to see the side-by-side video.
Few times does a post involving convoluted math and programming seem so clear. The diagrams help a lot, and the jump to 2D is mindblowing.
Through an analogy between learning CS, and how to play musical instruments, the author explains the value of reinventing the wheel: cloning other people’s projects allows you to learn useful patterns as you go. Start by mimicking, and continue adding your own features. The important part is putting your fingers to work. For example, I got my start with Michael Hartl’s Rails Tutorial, and modified it bit by bit to fit my needs. One of the best pieces I have read on how to “level up” as a software engineer.
Speed is rarely the reason to pick a programming language these days. See below.
Mostly, its a matter of taste. See above.
The machine learning inspired cousin to Fizz Buzz in Too Much Detail. You shouldn’t miss this one, even if your knowledge of ML is minimal.
The legal field is not very technologically enabled. As Casetext’s Jake Heller points out, “We’ve all seen this story. Whether it’s restaurants or encyclopedias, this is going to be replaced by an open knowledge solution.” The question is, which of all these services will win the market (full disclosure, my girlfriend works at Casetext, and I think they are doing great work at making legal data easily available).
While I enjoy reading about the breakthrough techniques in deep learning, applied machine learning, with weird and fun objectives and non-standard datasets is much more exciting.
The article talks about topics beyond management, but spends a good chunk of time discussing why projects with many moving pieces, many stakeholders, and many contributors are hard to do right. Mostly, because people are hard to understand. If you understand people, you’ll be a better engineer, better designer, and better manager.
Incentives…
It is weird when you can’t credit an author because their work doesn’t list their name. </br> As a side note, tweeting this got me into a strange twitter fight.
Was not expecting Uncle Bob to finish on that note. The history of programming languages is a big question mark for me. If you have a good book/blog post to recommend on it, please send it my way.
A good explanation of neural networks by example. It is amazing how quickly the toy problem of learning a couple of weights, basic high school math, becomes untractable.
Reminded me of Cesar Hidalgo’s book, Why Information Grows. At some point info HAS to be spread out across brains in the organization.
One of those lists that invariably will be printed out, and pinned to a cube, by a grumpy coworker.
To be honest, I haven’t finished reading this, but it was profusely recommended by randos on HN and coworkers alike. The preferred stack, and the JS framework du jour might have changed since then, but the basics are still the same. This essay tries to explain distributed systems fundamentals from “the log” up.
Even though I didn’t take a regex class, the similarities with my stochastic modeling class are stark. Now I want to learn more!
We can always be better, smarter, etc. Watson talks about why he shares what he learns: one step at a time, helping others along the way, understanding that there is always more than we can process.
Building software is hard. Learn from others’ mistakes.
{kind=link}